Site hosting news, tutorials, tips, How Tos and more

The latest version of these applications are now available in the control panel app installer:
Visit Winhost to learn more about our application hosting solutions
The latest version of these applications are now available in the control panel app installer:
Visit Winhost to learn more about our application hosting solutions
As we move forward into 2021, I wanted to do our quick look back on 2020 and talk a little about some of the enhancements we introduced.
EmailBackup – Your Email Backup Solution
We introduced a cost-effective EmailBackup solution that can automatically backup virtually any email box – from your email hosted at Winhost to other email boxes at other hosts to Gmail and Office 365.
We are also offering email backups for 30 days free so you can test it out and see if it is right for you.
O365Backup – Your Office 365 Backup Solution
For those using Office 365, we launched a comprehensive Office 365 Backup solution. This service will automatically backup your email, attachments, calendar, contacts, tasks, OneDrive, SharePoint, Groups and Teams. There are search and restore tools available.
You are welcome to test the O365Backup solution for 30 days free to see if it is right for your needs.
.NET Core
We’ve kept up with the .NET Core releases – making .NET Core 3.x available on our platform. Recently, we introduced support the .NET 5 (or ASP.NET Core 5 – Microsoft is dropping the “Core” moniker)
SQL 2019
We introduced SQL 2019 into the mix of databases we support.
PHP
We added support for PHP 7.4 and updated PHP 7.3.x and 7.2.x
Application Installer Updates
As usual, we kept as up-to-date as possible with the application versions in our Control Panel Application Installer
Maintained Our Great Service
When the Covid 19 pandemic hit, we quickly transitioned to a remote workforce and we’ve been operating this way since March 2020. Of course, we had to deal with a variety of issues and learn how to better operate in this type of situation. But I’m glad to say that we’ve been able to still deliver on our hosting service promise and even introduce some useful services in 2020.
THANK YOU!
We thank all of our customers and we wish you a safe, healthy New Year!
Visit Winhost to learn more about our ASP.NET hosting solutions
Microsoft recently released .NET 5.0. Note that Microsoft is changing their naming convention for .NET. Instead of calling this new major release .NET Core 4.0, they went with .NET 5.0 (or you may see it out there as ASP.NET Core 5.0).
Naming convention aside, we want to let you know that ASP.NET Core 5.0 is now available on Winhost’s Windows 2012 and Windows 2016 hosting platform. We support framework dependent deployment (FDD) for applications created with ASP.NET Core 5.0.
Note: If you cannot use framework-dependent deployment for any .NET Core version, remember that you can always publish using self-contained deployment (SCD). (For example, we show how to use self-contained deployment with Visual Studio 2017, in our knowledge base.) If any customers have questions about deployment, contact technical support.
Visit Winhost to learn more about our ASP.NET Core hosting solutions
.NET Core
On our Windows 2012 and Windows 2016 web servers, both .NET Core 3.1.9 and .NET Core 2.1.23 are now available for framework dependent deployment (FDD).
Note: If you cannot use framework-dependent deployment for any .NET Core version, you can always publish using self-contained deployment (SCD). (For example, in our Knowledge Base, we show how to use self-contained deployment with Visual Studio 2017.) If any customers have questions about deployment, contact our tech support.
PHP
On our Windows 2012 and Windows 2016 hosting platform, we have made the following updates to PHP versions:
Visit Winhost to learn more about our ASP.NET Core hosting and PHP hosting solutions
The latest version of these apps are now available through the Winhost control panel application installer:
Visit Winhost to learn more about our application hosting solutions
We were notified by our upstream provider about a recent rise in hacking activities related to older Telerik Web UI Controls that were integrated into older Sitefinity and DotNetNuke applications and may have been used in older custom ASP.NET web applications. Since the warning, we have indeed seen sites hosted at Winhost getting hacked due to this vulnerability, so we wanted to let you know about it.
Some in the security industry are calling this hack Blue Mockingbird and Telerik has even posted about this issue on their blog.
In general, what hackers are doing is using a built-in function of the Telerik Web control – a function that the website may also use – to upload files to the site. Once uploaded, the hacker uses the files to do malicious stuff or the files may just sit there and do nothing (until some future time when the hacker decides to wake it up).
Apparently, there are many different hackers and hacking groups that are exploiting this vulnerability. If the hacker messes up the customer’s website or uploads some phishing site, the customer and/or the host would probably notice and deal with it. But the major issue is that many times the files that are being uploaded are doing nothing – so the site owner doesn’t know something was uploaded to their site and the host won’t know the site got hacked. The hack is clever because its use of the Telerik control looks legitimate.
To deal with this hacking activity, we are monitoring our intrusion prevention system more diligently and made updates to our server security. And our staff are actively looking out for any indication of hacking activities.
Sitefinity and DotNetNuke users
If any customers are running Sitefinity or DotNetNuke, get in contact with our technical support and we can check if your site is vulnerable. If your site is vulnerable, we can discuss next steps in how to deal with it.
Custom Applications Using Telerik Web UI Controls
If you use Telerik Web UI control in your custom ASP.NET web applications, get in contact with our technical support and we can check if your site is vulnerable. if your site is vulnerable, we can discuss next steps in how to deal with it.
If you have any questions or concerns, feel free to contact us.
Visit Winhost to learn more about our Windows hosting solutions
Nopcommerce 4.3 was released and with it, the ability to use a MySQL database. In this post I’ll be showing you how to configure your nopCommerce 4.3 with a MySQL database.
Like many applications, nopCommerce is installed in two steps. First, you install the nopCommerce application into your site and then you complete the software configuration by providing information through an Installation Wizard that you access through your web browser.
You can use our Application Installer to install nopCommerce 4.3 in your site. Follow the instructions in the first part of this Knowledge Base article to get the initial nopCommerce install done but you won’t need to create a new MS SQL database. The rest of the information in this blog post will give instructions on how to create a MySQL database and how to complete the nopCommerce Installation screen.
Now that you have installed nopCommerce in you site, we want to pull up the nopCommerce Installation screen to finish configuring nopCommerce. Assuming that your domain is not yet resolving to Winhost, you can complete the nopcommerce configuration using the Secondary URL we provide you. Here is how to find the Secondary URL.
Enter the Secondary URL into your web browser. You will be presented with the nopCommerce Installation screen. In this screen, you will provide specific information about your store and hosting account to finish configuring the application.
Enter the following information into the nopCommerce Installation screen.
Next, you need to create a MySQL database through the Winhost control panel. Here are step-by-step instructions.
Now, you need to specify that you will use MySQL as your database and tell the nopCommerce application where the database is and how to access it. So, go back to the nopCommerce Installation screen and have the Winhost Control Panel MySQL section open in another browser tab so you can go back and forth to get and enter your information.
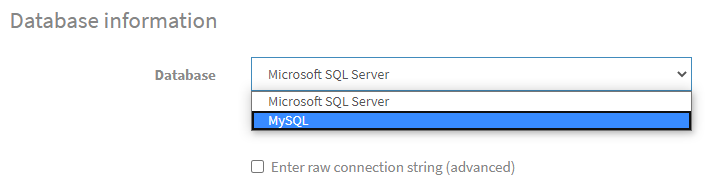
In the Database Information Section of the nopCommerce Installation screen, click on the Dropdown menu and select MySQL as shown below:
Click on the Install button and wait for the installation to complete. This will take a few minutes.
Enjoy
Visit Winhost to learn more about our nopCommerce hosting solution